电商系统中的高并发库存扣减算是一个比较经典的难题,网上关于这类话题的文章不少,不过很少有看到有系统讲解,以及提供一个真正可以落地的方案的。刚好前段时间和朋友讨论了一下这个话题,受益匪浅。趁着脑子思绪还比较清晰,在这篇文章做一个系统的梳理。
前提
本文预设场景:
- 服务端架构是分布式架构,即订单服务,商品服务是不同的服务,部署在不同的节点。
- mysql作为数据库
- redis作为内存数据库
如果读者掌握下面的一些知识,阅读本文可能会更加流畅。
- Event Sourcing
- Redis Lua脚本原子操作
- Redis 锁的基本原理
基于数据库的库存扣减
数据库锁
我曾在某论坛看到过一种观点,直接使用数据库无法实现库存扣减,这其实是一种误解。使用数据库的锁是有能力做到库存扣减的,比如:
update goods set quantity = quantity - 1 where id = ${id} and quantity > 0
上面的update语句是原子的,根据数据库返回的effectRows,可以判断这次更新有没有执行成功,做对应的commit或rollback操作。那么为什么很多人不会推荐直接用数据库锁呢?因为它的效率非常低,在高并发的环境下,很容易造成系统卡死。
数据库瓶颈
-
高度竞争下,事务串行化,并发反而成了一种负担(线程上下文切换等)
同一条记录的 X 锁只能被一个事务持有,其余全部进入锁等待队列,吞吐量直接退化为“单线程 + 事务持锁时间”
-
mysql的死锁检测有额外的开销
-
数据库读写是Disk IO
- 毫秒级的读写,叠加事务串行化,吞吐量受限于单个事务的执行速度
- 写放大,写入一条记录还会伴随着索引、undolog、redolog的写入
-
连接数限制
数据库系统的连接数通常不会很大,超过后就会拒绝服务
对于一个OLTP系统而言,latency是最重要的指标。如果大量的并发写入请求打到数据库,因为事务串行化,造成等待时间过长,数据库连接数会快速耗尽,导致数据库无法继续提供服务,这显然是很难让人接受的。
基于Redis的分布式锁
锁的粒度
Redis是一个内存数据库,单个操作延迟极低,能支撑很高的并发。同时,redis提供了一种set nx的语法
set "global_lock" "9a00ca3e-cb19-4cce-9f5c-2e94d5dce7c2" nx
上面的指令,使用nx,确保global_lock这个key不存在时,才会设置成功。这就是redis锁实现的根基。set nx的结果可以判断锁是否被持有。
redis锁是网上最常见到的解决方案,它的执行路径大致如下:
def createOrder():
with redis.lock("global_lock") as lock:
successful = goods.updateStock(id, quantity)
if successful:
order.create()
通过redis的锁,可以把大量的并发拦截,防止并发涌入到数据库中,造成连接数被快速耗尽。读者可能已经发现,上面的global_lock锁粒度太粗了,吞吐量反而会下降。因为不相关的sku也要竞争同一个锁,相当于把所有sku扣减都串行化了。那么如果我们把粒度改为sku级别呢?
def createOrder():
with redis.lock(sku_id) as lock:
successful = goods.updateStock(id, quantity)
if successful:
order.create()
锁粒度改为sku级别后,一定程度上缓解了吞吐量问题,但如果我们认真审视上面的方案,可以发现它并没有解决吞吐量的问题: 针对热门商品(即同一sku),事务依然退化为了单线程。大量的并发在等待持有锁那个事务释放,吞吐量受限。
细粒度的锁还带来了一个新的问题: 锁的实现复杂度变高。
用户下单时,通常是几个sku同时下单,比如
User A:
[
{
"sku_id": 1,
"quantity": 2
},
{
"sku_id": 2,
"quantity": 1
},
]
User B:
[
{
"sku_id": 2,
"quantity": 1
},
{
"sku_id": 3,
"quantity": 1
},
{
"sku_id": 1,
"quantity": 1
},
]
如果有两个用户按照上面的方式下单,稍不注意可能就会造成死锁。
A: lock 1
B: lock 2
A: wait B
B: lock 3
B: wait A
虽然我们可以对sku id进行排序,按顺序加锁避免死锁问题。但如果锁的实现是每个sku一把锁,当用户下单的sku很多,锁的可靠性会直线下降。很快我们会发现,可能要实现一个类似于mysql的gap lock避免这类问题。
由此可见,锁粒度越细,实现难度可能是指数上升的。
原子提交问题
即便我们解决了锁的复杂度问题,还不得不面对一个难题: 原子提交。
因为order和goods是不同的服务,一般的业务流程是同步的,即下单完成后要立即跳转到订单页面。所以当存扣减成功后,需要保证order和goods同时成功或失败。如果引入2PC或TCC之类的分布式事务,那么单个事务的latency会雪上加霜。
优点
利用成熟的基础设施,实现简单,适用于单品秒杀这种场景。
缺点
吞吐量有限,仅适用于单品秒杀,如果允许一次下多个sku,锁的实现复杂度会很高
基于内存的库存系统
回顾刚刚提到的方案,都被数据库系统操作慢这个特性影响了系统整体的吞吐量。因为数据库操作都是Disk IO,延迟无法做到很低。那么,如果我们把整个库存搬到内存中去实现呢?听起来似乎激进到不可行,但这就是这一章节的主题。
内存是一种不稳定的存储介质,但通过一些工程手段,可以最大程度避免出现超卖和少买问题(降低到一个可接受的范围)。
库存状态机
从抽象的角度看,sku的库存变化就是某个sku的状态变化。如果我们把sku看做一个状态机,库存变化就是一个状态变更Event,再通过Event Sourcing的方式把所有event apply到DB或memory中对应的sku,就能实现状态一致。库存的状态变化主要来自于两个操作:
- 商户(平台)采购新的sku补充库存
- 用户购买消耗库存
sku补货流程
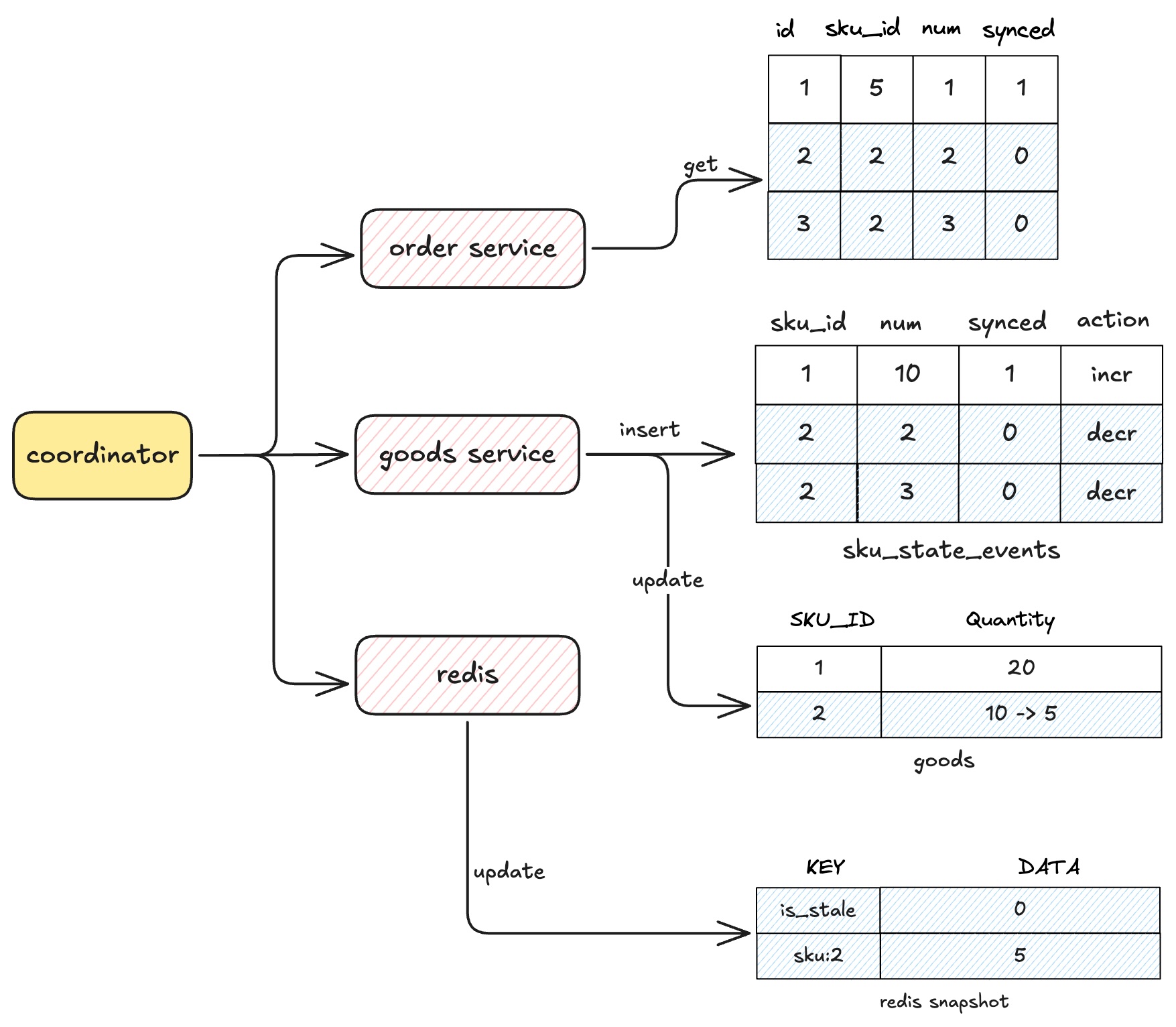
当sku完成了采购流程,会生成一条库存记录插入到sku_state_events表中,同时也会更新sku表中quantity字段。如下图:
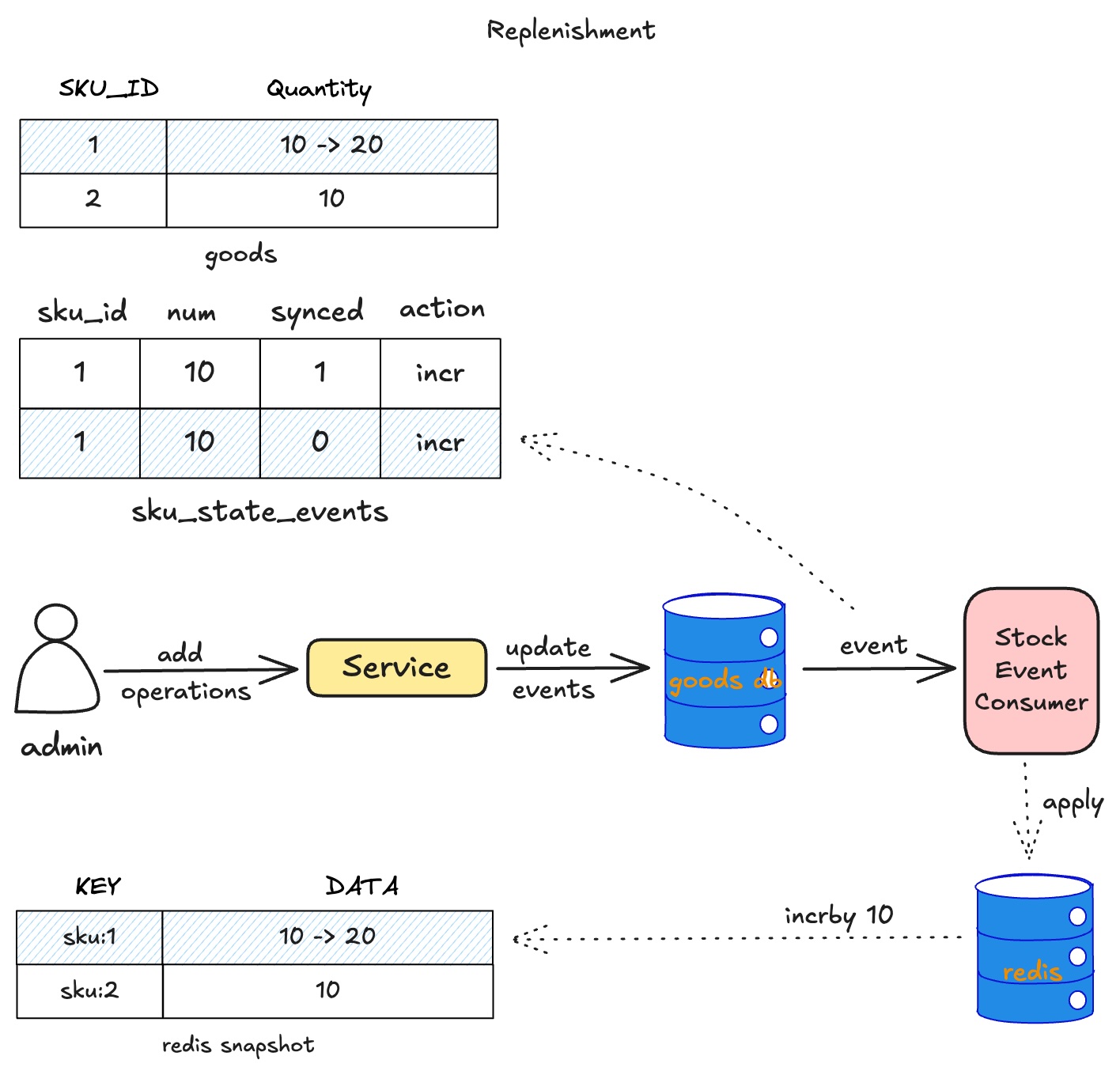
stock event consumer会消费sku_state_events的事件,把状态变化提交到redis中,让redis的snapshot保持最新。当然这里最好也利用上lua脚本,做好幂等,防止重复消费事件。
下单流程
另一种库存变化路径是用户侧下单操作,当用户提交订单:
- 先判断redis中的库存是否满足条件
- 满足后立即创建一个订单,如果下单失败,记录到一个本地账本,定时上报对账
- order_item中每一条记录对应了一个sku状态变化event
- 通过stock event consumer把这些状态apply到对应的sku中
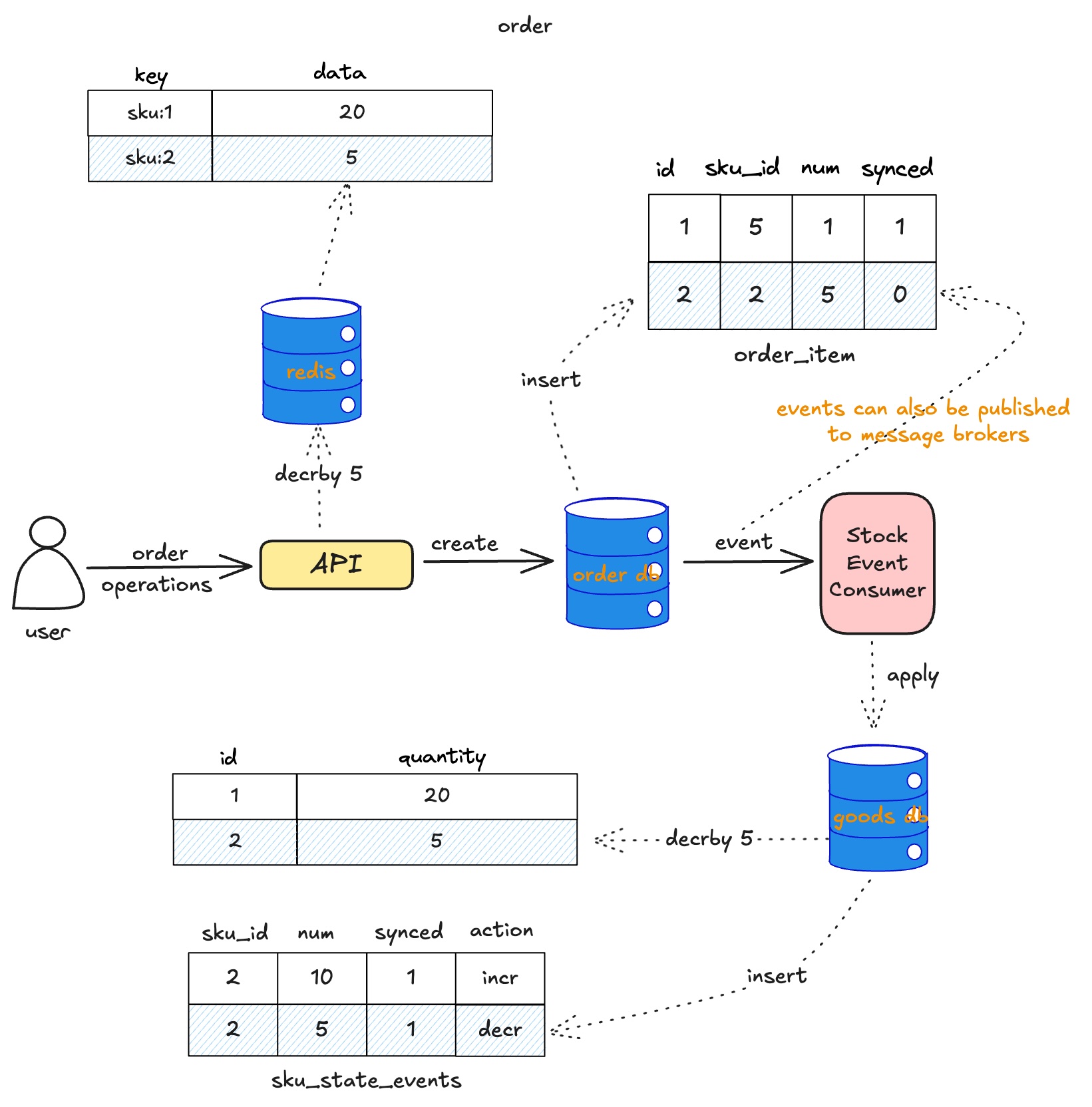
上图可以看出,库存扣减业务是在redis中进行,数据库不再参与这部分业务,这样做解决了两个很大的问题:
-
数据库IO慢的问题
因为使用了redis进行库存扣减,吞吐量高延迟低。而数据库它只作为Source of Truth,即便它的库存一致性存在一些延迟,也不会影响业务正常运作。
-
原子提交问题
order_item中的记录会转换为sku的状态变化event,使用Event Sourcing就可把变更的库存同步回goods db中,不需要原子提交也能保证库存一致性。
处理超卖
因为Redis是内存数据库,如果发生意外,一定会出现数据不一致的情况(断电,异常退出,执行failover等),所以需要引入一种机制,用于判断redis中的库存数据什么时候是可信的。
熔断
当业务端发现redis的数据不可信时,需要执行熔断操作,不再执行库存扣减逻辑,等待coordinator执行完故障恢复(即强制库存同步),才恢复正常。
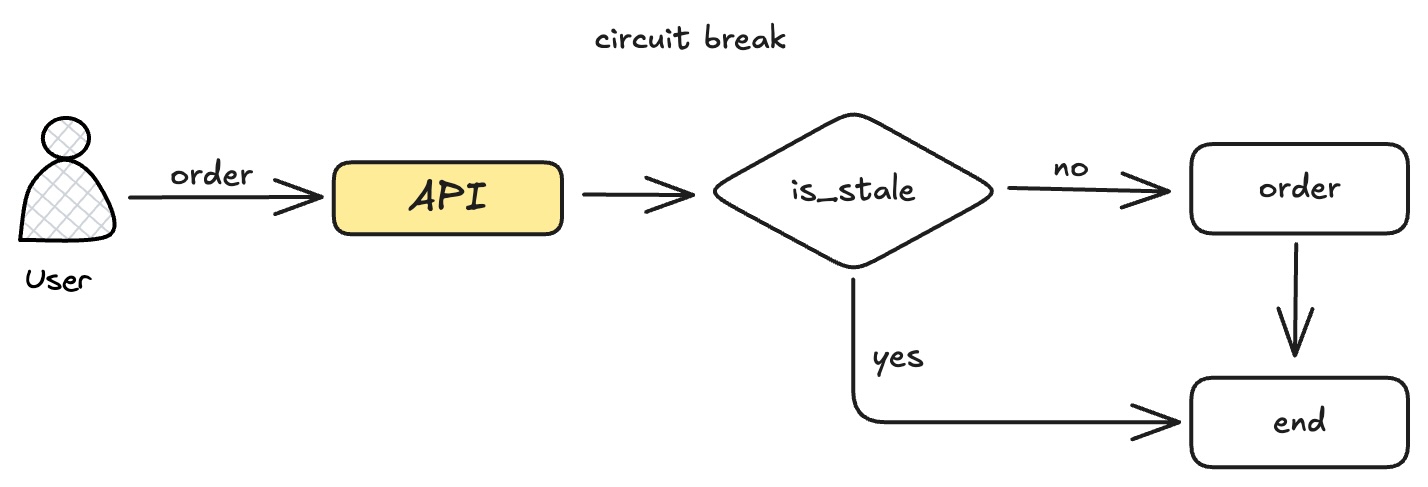
执行库存扣减的lua脚本,前面加上一个if判断。如果发现当前快照是不新鲜的,就拒绝业务端写入。
local stale = redis.call("GET", "is_stale")
if (not stale) or (stale ~= "0") then
return 0
end
现在引入一个新的角色,coordinator,负责维护redis的stale状态。当它发现redis快照状态是不新鲜的,就执行强制库存同步。根据redis的部署架构,可分为几种不同的设计。
单节点
单节点的redis,熔断方案非常简单。只要我们每次启动redis时,同时执行一条命令,把is_stale这个key设置为1,就能直接让业务端执行库存扣减时触发熔断。直到coordinator执行完成强制库存同步再恢复为0。
哨兵
在redis哨兵架构下,sentinel执行failover时不受我们控制,情况开始变得复杂起来,无法继续使用is_stale这种简单的方式执行熔断,需要转变一下思路。
现在给master设置一个master:epoch的key,value是redis sentinel config epoch。啥是epoch呢?可以看看redis官网的定义:
Sentinels require to get authorizations from a majority in order to start a failover for a few important reasons:
When a Sentinel is authorized, it gets a unique configuration epoch for the master it is failing over. This is a number that will be used to version the new configuration after the failover is completed. Because a majority agreed that a given version was assigned to a given Sentinel, no other Sentinel will be able to use it. This means that every configuration of every failover is versioned with a unique version. We’ll see why this is so important.
epoch是一个单调递增的数字,每次sentinel执行failover时,需要majority sentinels的同意,更改这个数字,成功后存入配置中。这个epoch起到一个类似于fencing token的作用,后续会详细聊到。
在执行库存扣减之前,现在我们需要检查epoch跟之前是否一致
local epoch = ARGV[1]
local current = redis.call('GET', 'master:epoch')
if (not current) or (epoch ~= current) then
return 0
end
-- ...
引入epoch主要服务于下面两个场景:
- 给coordinator判断什么时候该执行强制库存同步
- 降低脑裂带来的影响
其中脑裂是我们接下来要讨论的重点。在sentinel执行failover时,主要会有下面两类场景:
-
旧的master真的挂掉了
这种情况对我们业务影响不大,因为所有clients都将会连上新的master,不会同时出现2个master
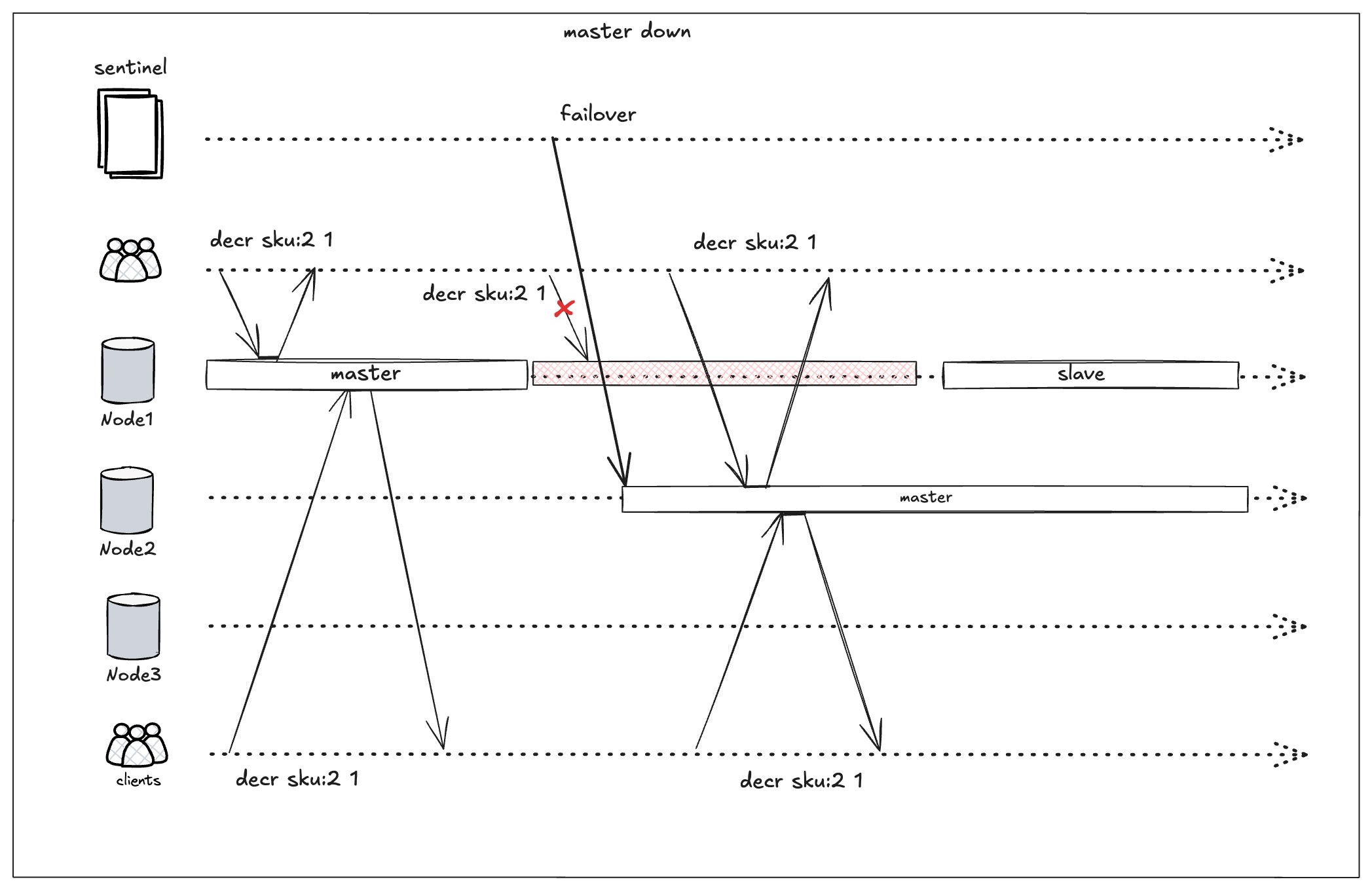
-
发生网络分区,并非真的挂了
这种情况对业务会产生很大的影响,因为可能会有一个时间窗口同时存在两个master节点,这就是脑裂。如果两个节点同时进行库存扣减,会出现超卖。必须要通过一些手段尽可能降低这种情况带来的影响。
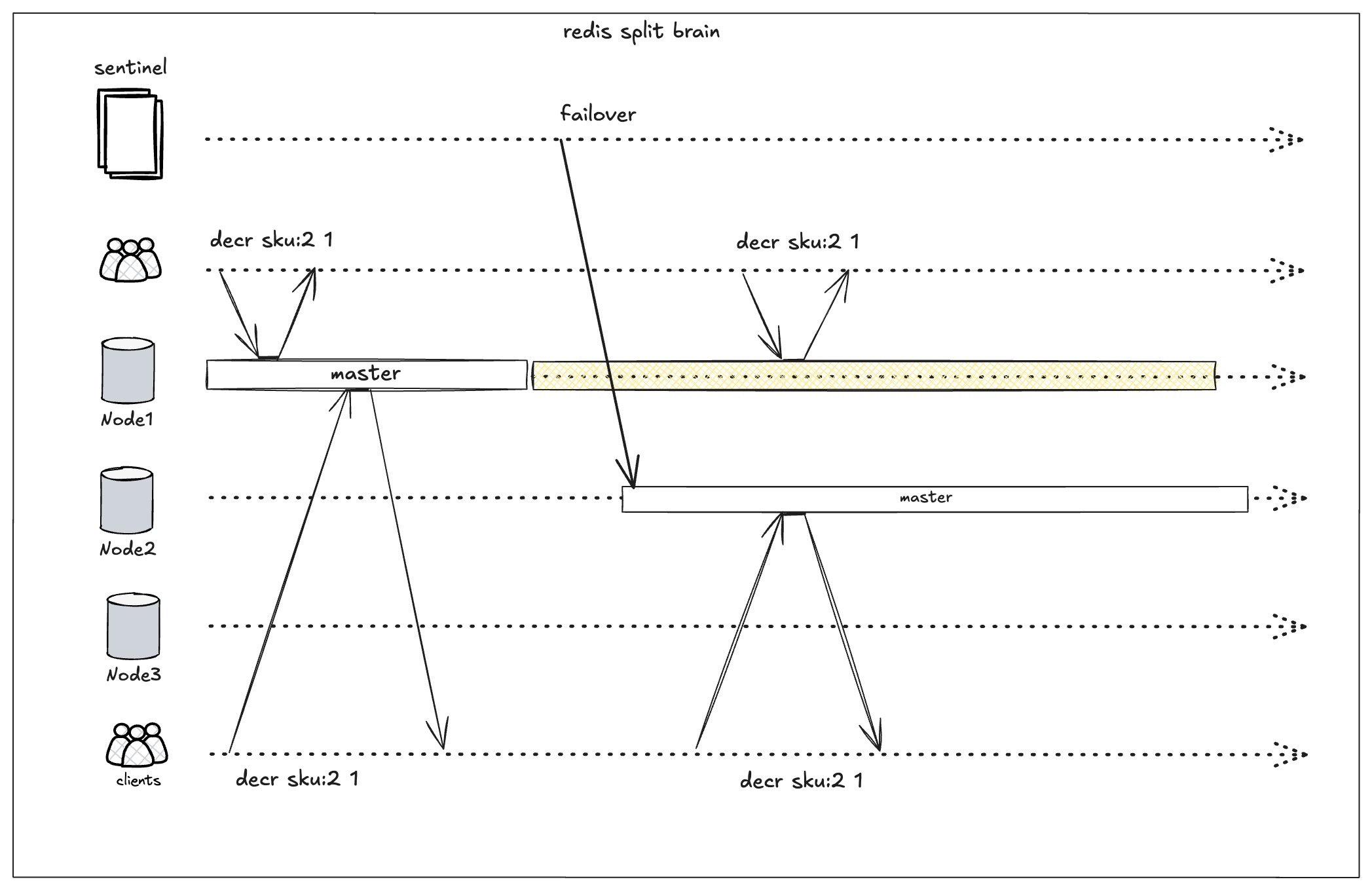
上面说的降低,是因为在redis中脑裂是无法避免的,因为它写入并不需要quorum的确认,当发生网络分区,就有可能会同时存在两个master,我们只能尽可能把影响降低到一个可接受的范围内。
处理脑裂
既然无法避免出现两个master,那就只能通过一些手段,在出现两个master时,只让其中一个工作,只要不是两个master同时工作,就不会造成超卖。可以在下面几个点上做努力:
-
redis sentinel配置
redis官方提供了两个配置用于缓解脑裂写入
min-replicas-to-write
min-replicas-max-lag min-replicas-to-write: 要求 master 至少有 N 个“健康副本”(replica)存在时才接受写入。
min-replicas-max-lag: 这些副本与 master 的复制心跳/ACK 延迟(lag)不超过 M 秒;超了就不算“好副本”。
min-replicas-to-write 1 min-replicas-max-lag 10如果连 1 个“好副本”都保证不了,就停止接受写入;如果是网络分区导致副本 ACK 超过 10 秒收不到,旧 master 大约 10 秒后就会拒写。
当然这个保证不了什么,只能做一个最坏情况的保障。
-
业务端的熔断
业务端需要维护一个和sentinel的健康状态检查,周期性向sentinels询问当前最新的master和epoch信息。如果失联了一定的时间,则认为unhealthy,在业务端触发熔断。
需要注意的是: 在询问sentinel时,需要至少同时询问majority个sentinel节点(比如3就至少问询2个,5就至少询问3个),才能保证信息的可靠性。 下图展示了一种情况,因为网络分区,sentinel2被隔离,返回的是一个旧的epoch。
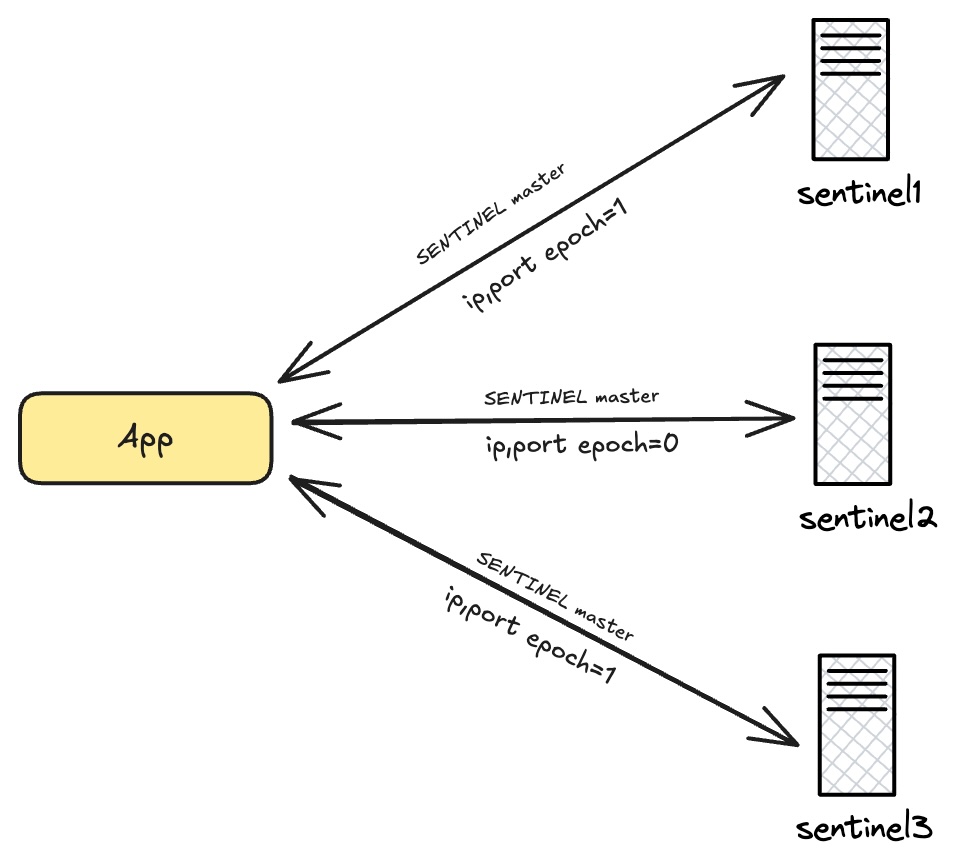
-
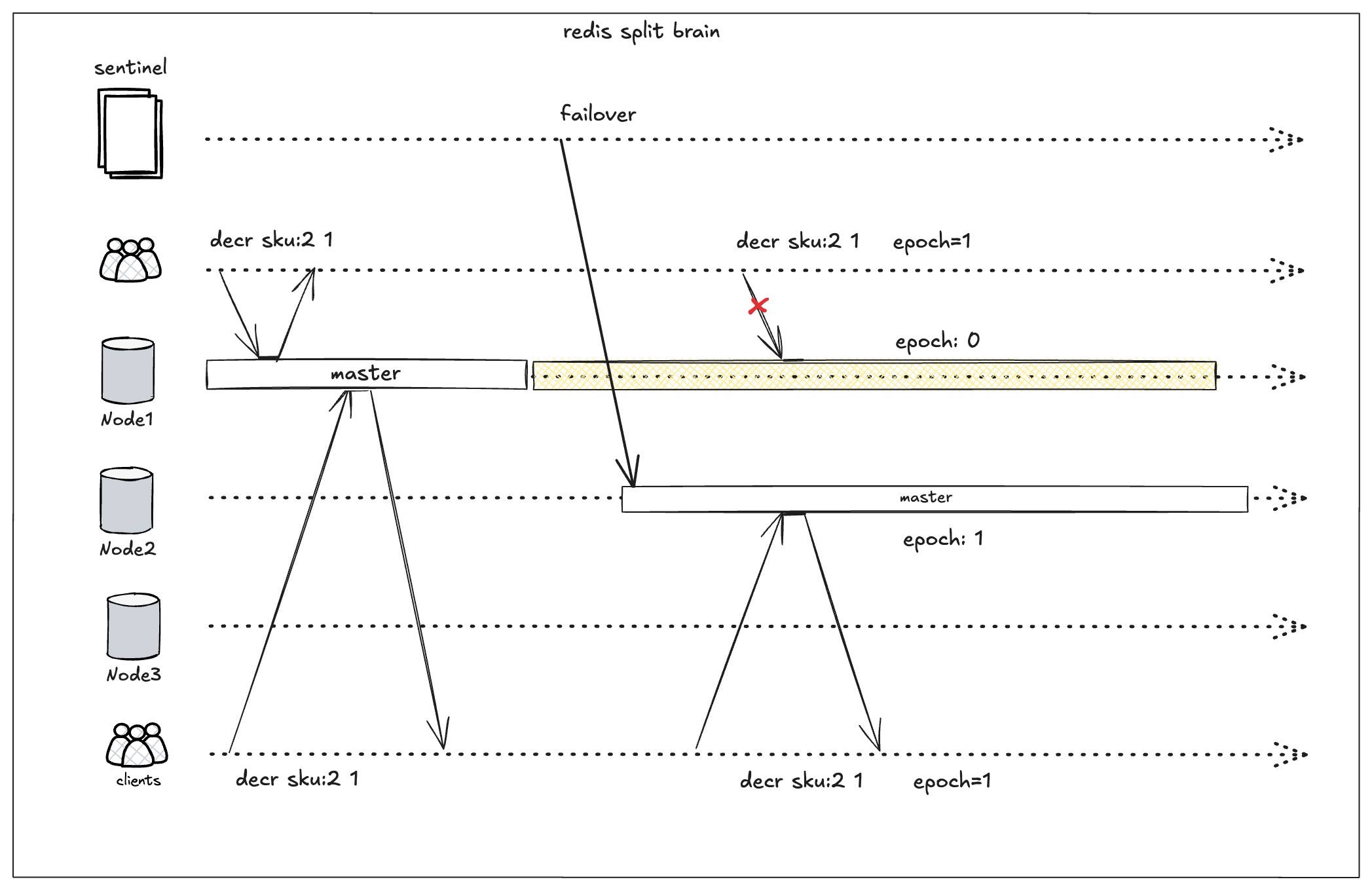
redis lua脚本判断epoch触发熔断
在上一步,业务端维护了一个最新的epoch。在执行库存扣减时,传入epoch,在redis lua中判断epoch是否一致,不一致即拒绝写入。下图就是旧的clients连接到旧master执行库存扣减,被epoch拒绝执行。
long pause问题
通过业务端和redis lua的熔断,还远不能覆盖真实的情况,比如经典的long pause问题。在现实世界中有一些情况会造成进程长时间暂停,比如:
-
long gc pause
如果程序使用的是有gc的语言,gc的STW可能会导致进程长时间暂停
-
OS Swapping
在内存不足时,os swapping可能会导致进程卡住
-
docker的cgroup 限额导致的 throttling
如果程序跑在容器中,可能会因为cgroup 限额导致的 throttling而暂停进程
一旦发生上面的情况,就可能会导致两个master同时在做业务扣减。设想下面场景:
- client刚执行完了一次健康检查,得到epoch = 1
- 此时刚好因为long gc进程暂停了5s,在这5s发生了failover,选举了新的master,epoch = 2
- client所连接的master因为网络分区,epoch还是1
- long gc结束,进行业务扣减。两个master同时在做库存扣减,就可能会超卖。
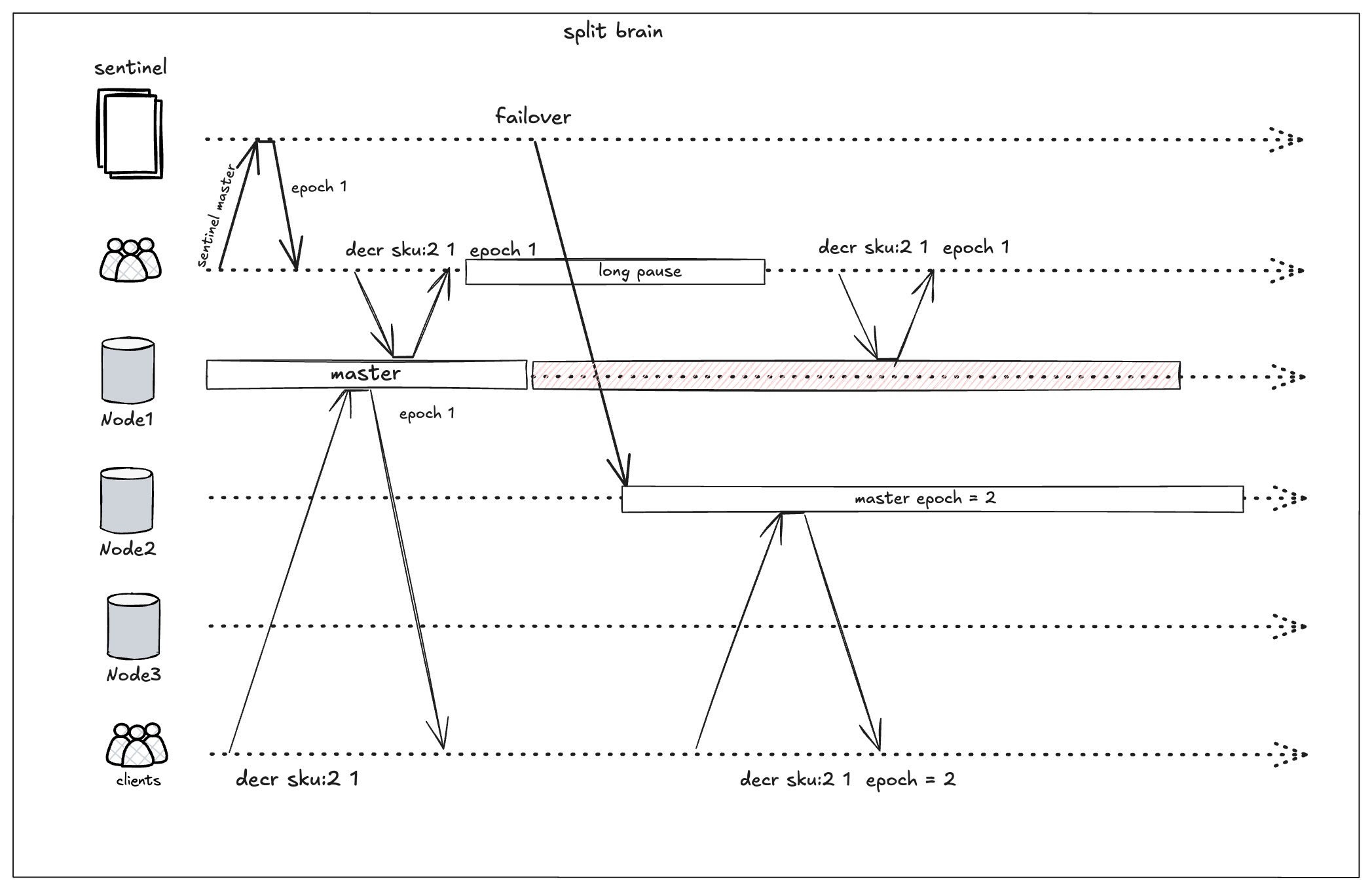
为了缓解long pause带来的问题,client在执行健康检查之前,可以询问当前的master当前的时间,维护一个时间戳字段。在执行库存扣减时,传入这个时间戳,同时lua脚本多加一段逻辑:
-- ARGV[1] checked_at
local t = redis.call("TIME")
local now = tonumber(t[1])
local checked_at = tonumber(ARGV[1])
local max_age = 5
if (not checked_at) then
return {err="BAD_ARGS"}
end
if (now - checked_at) > max_age then
return {err="STALE_VIEW"}
end
上面的情况可以缓解long pause带来的问题。但也只是缓解,在下面情况还是会出现超卖:
-
failover发生在timeout的时间窗口之内
如果gc了3s,这3s内完成了failover,还是出现了2个master同时工作。
-
时钟回拨
上面的时间都是依赖物理时钟。在分布式系统中,物理时钟都是不可靠的,它会有偏差,需要定期校准。所以会出现下面情况:
- client获取到了最新的epoch
- 发生了long pause,暂停了10s
- redis发生了时钟回拨,时钟回到了10秒之前
- lua脚本校验时间通过
上面两点,可以通过强制加长新master恢复服务的时间缓解。比如coordinator在执行强制库存同步时,时间不能低于redis timeout的2-3倍。加长新master的启动时间,尽可能避免同时2个master同时在进行库存扣减。
集群
从redis哨兵架构能看到,方案设计已经非常复杂了,而且也无法完全避免超卖问题。如果使用redis集群,实现难度会上升一个数量级,主要涉及到:
- redis的lua无法保证跨分片的原子性,订单的sku分布在不同的分片上就无法实现原子操作
- 集群的节点加入,退出,rebalance也加大了实现redis和db之间数据一致性的难度
所以我觉得,这个方案不适用于redis集群的架构。因为最终可能会复杂到难以实现。
故障恢复
要进行故障恢复(即强制同步库存),首先需要明白什么时候该执行。在单节点的架构下,只需要不断轮询is_stale这个值即可。如果是sentinel,则需要向majority询问epoch和master信息。
当coordinator发现redis的状态异常,它就会启动业务端故障恢复,执行强制库存同步。它需要完成以下几个步骤:
- 把order_item中所有未同步的sku全部处理完成
- 把sku_state_events中所有待处理的事件处理完成
- 把redis熔断状态取消
经过上面几个步骤,goods db中所有的sku状态已经正常,再把这部分状态强制刷新到redis中,成功后,redis就拥有了最新且正确的snapshot。
当完成所有步骤后,coordinator把redis的状态设置为ready(is_stale=0或master:epoch更新为当前epoch)。此时业务端的熔断也会结束。
处理少卖
少卖主要发生在,当redis库存扣减成功后,创建订单出现异常,这里又分为两种情况:
-
成功插入本地账本
如果成功插入本地账本(sqlite或MQ都行,看取舍),那么可以定时上报本地账本的异常数据给coordinator,让它执行对账。
-
本地账本都无法插入
如果因为断电或进程异常退出或重启等造成这条记录永久丢失,那么需要一个更重的对账机制。比如每天凌晨3点,拉取前一天交易的所有sku,比较当前sku和db中的库存是否一致。为了正确性,可能不得不停止下单一些时间(可能几分钟到10分钟),是一个很重的操作,这个就要看取舍。
缺点
1. 牺牲部分可用性
单节点的redis虽然可以避免超卖问题,也因此存在单点故障。一旦redis节点挂掉,整个服务就会处于不可用状态。
如果采用sentinel架构部署redis,一定程度上能提高可用性。但如果发生了网络分区,局部分区的节点无法联系上sentinel,无法得知当前的master节点是谁,这部分节点就变得不可用,无法下单。(否则可能会因脑裂造成超卖)
在极端情况下,如果网络不稳定在频繁执行failover,服务的可用性也会变得很糟糕。
2. 对账复杂度
写入local db之前,如果进程挂掉或断电,就丢失了。这就需要依赖一个更重的账本去对账,生成一些补偿性的stock_state_event插入到数据库中。如果系统的单量很大,这个操作的耗时也会线性增加,暂停下单的时间也会增加。
3. 超卖问题
在redis sentinel架构下,还是存在一个时间窗口会造成超卖问题。这个就是该方案可用性的一个代价。如果想绝对避免超卖,就要牺牲可用性,换到单节点的redis,这个只能看取舍。如果需要高吞吐和又不想牺牲可用性,那只能在用户协议中规定好赔偿协议。
可以看到,sentinel模式下,用了诸多复杂的设计,都无法从根本解决超卖问题。根本原因还是我们想要在sentinel这样一个AP的系统中构建一个CP的保证,这个基本上是不可能做到的。
优点
- 实现了高吞吐量,低延迟的同时,在数据一致性上也取得了一个平衡。把超卖和少卖控制在一个可以接受的范围。
- 能支撑1万到几万个TPS,尤其擅长应付秒杀这种海量的tps但实际库存只有很少的场景。
- 都是使用通用的基础设施,不需要投入太多资源也能使用和维护。
基于AliSQL的Inventory Hint
在介绍数据库方案的时候,我们列举了一些数据库的瓶颈,其中主要是:
- 数据库的磁盘IO瓶颈影响了整体吞吐量
- 一些写放大,死锁检测等增加了额外的开销
那么有没有办法从数据库层面去做一些优化呢?这个就是AliSQL做的事,它在优化了数据库的内核,让单个事务的执行时间变得更短,从而提升整体的吞吐量。
Inventory Hint
hint特性是mysql中用来控制优化器的一种手段。假设在一个join查询中,我们想控制优化器使用hash join,就可以使用hint控制优化器的行为
SELECT /*+ BNL(t1, t2) */ *
FROM t1
JOIN t2 ON t1.c1 = t2.c1;
其中BNL(t1, t2)就是用 hint 控制优化器/连接算法。AliSQL也增加了几个专门针对库存扣减场景的hint,叫inventory hint。
语法
/*+ COMMIT_ON_SUCCESS */
/*+ ROLLBACK_ON_FAIL */
UPDATE /*+ COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL */ T
SET c = c - 1
WHERE id = 1;
使用了上面的hint,当update语句执行完后会立即提交或回滚当前事务,这相当于减少了单次事务的执行耗时,从而提升吞吐量。阿里官方声称,在一台90核 720GB(独占物理机型)中能达到3W的TPS。
当然如果只在事务提交方面做优化肯定还远远不够的,磁盘IO始终是一个瓶颈,内部应该还利用了cache,否则难以解释。不过目前披露的资料很少,没办法作进一步查证。
局限
inventory hint特性看着挺美好的,实际上它所适用的场景也是较为单一。使用它会导致事务立即被提交或回滚,这就意味着,如果它想和其他操作打包为一个事务,扣库存的操作必须要放在最后一步,否则因为hint的立即提交特性,无法保证数据的一致性。
设想一下,如果我们一次购入是多个sku,update的sql就可能要写成下面这样:
begin;
update goods set quantity = quantity - 1 where sku_id = 1 and quantity > 0;
update /*+ COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL TARGET_AFFECT_ROW(1) */
goods set quantity = quantity - 1
where sku_id = 2 and quantity > 0;
commit;
因为hint的特性,不得不写在最后一条sql,那前面一条怎么办呢?这种情况可能就退化为了原本的mysql中存在的问题。因为引入了这个inventory hint,说不定情况还会比原来更加糟糕,所以它局限性也挺大。
优点
一致性更强。
缺点
-
业务场景有限
如果是单品秒杀这种临时场景,那么用redis锁,设计一个分段锁也能以较小的代价实现较高的吞吐。
-
绑定死了阿里云生态
使用了AliSQL就意味着自己的业务绑死在阿里云生态,为了一个使用场景比较窄的业务而选择把业务架构绑死在一个云厂商,代价有点高。
结语
本文分析了好几种实现高并发库存扣减的方案,可以看出,没有一种是能做到完美的。而且,每一种方案,都是构建在一整套基础设施之上。即便是阿里的sql魔改了数据库内核,也不是简简单单用一个Inventory Hint就能在业务系统中实现很高的吞吐量。这也体现了分布式系统的复杂度和细节之多,没有业务实战真的很难体会其中的坑坑洼洼。