电商系统的高并发库存扣减
电商系统中的高并发库存扣减算是一个比较经典的难题,网上关于这类话题的文章不少,不过很少有看到有系统讲解,以及提供一个真正可以落地的方案的。刚好前段时间和朋友讨论了一下这个话题,受益匪浅。趁着脑子思绪还比较清晰,在这篇文章做一个系统的梳理。
前提
本文预设场景:
- 服务端架构是分布式架构,即订单服务,商品服务是不同的服务,部署在不同的节点。
- mysql作为数据库
- redis作为内存数据库
如果读者掌握下面的一些知识,阅读本文可能会更加流畅。
- Event Sourcing
- Redis Lua脚本原子操作
- Redis 锁的基本原理
How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Progranm
分布式系统的顺序一致性的来源就是Lamport大神的这篇文章,因为原始的PDF字体清晰度不好,我弄成了文字版的。实际上在CPU这种微观系统中实现顺序一致性也会很浪费性能,作者在最后也提到了更小粒度的顺序一致,比如Memory module级别降低到内存单元(Memory cell),对于其他的操作依然是out of order,这其实也由total order变为了partial order。
有兴趣的可以下载原文看: 点击查看原文。
Abstract–Many large sequential computers execute operations in a different order than is specified by the program. A correct execution is achieved if the results produced are the same as would be produced by executing the program steps in order. For a multiprocessor computer, such a correct execution by each processor does not guarantee the correct execution of the entire program. Additional conditions are given which do guarantee that a computer correctly executes multiprocess programs.
Index Terms-Computer design, concurrent computing, hardware correctness, multiprocessing, parallel processing.
A high-speed processor may execute operations in a different order than is specified by the program. The correctness of the execution is guaranteed if the processor satisfies the following condition: the result of an execution is the same as if the operations had been executed in the order specified by the program. A processor satisfying this condition will be called sequential. Consider a computer composed of several such processors accessing a common memory. The customary approach to designing and proving the correctness of multiprocess algorithms for such a computer assumes that the following condition is satisfied: the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program. A multiprocessor satisfying this condition will be called sequentially consistent. The sequentiality of each individual processor does not guarantee that the multi-processor computer is sequentially consistent. In this brief note, we describe a method of interconnecting sequential processors with memory modules that insures the sequential consistency of the resulting multiprocessor.
Java多态原理 - JVM的静态分派和动态分派
0. 前言
多态是面向对象编程模型中一个核心概念,它可以帮助我们写出更具有弹性的代码。相信每个Java开发者都对多态的使用非常熟练,不过可能大多人对于”多态”这一概念的理解仅是浮于表面,对它内部的调用过程以及实现原理缺乏更深一步的认识。本文将对多态的实现原理抽丝剥茧,带大家深入理解多态。
后记: 这篇文章在我的草稿中躺了很久,近期翻出来整理成了一篇文章。近一年来很少写Java相关的东西,一来是深度有限,不想把时间花在没多大意义的地方上跟别人卷;再者还有很多感兴趣的课题想去学习和研究,比如多读一些分布式系统的论文、CS的一些理论等。 学习真正的知识总是缓慢而枯燥的,过程或多或少会感到煎熬,掌握后就会觉得相当充实和充满趣味。以后可能会很少写这类文章了。
1.多态的种类
多态(Polymorphism)这个术语在不同的上下文中会有不同的含义。在类型学说(Type Theory)中,多态分为好几个种类,其中最常见的有3种类型,分别为Ad hoc polymorphism、Subtyping,Parametric polymorphism ,而Java实现了这3种类型的多态;在OOP(面向对象编程)中,我们常说的多态指的是类型学说中的Subtyping。
为了方便理解多态调用原理,本文着重介绍前两者。后者因为涉及到类型擦除和单态化(monomorphized),碍于篇幅,不进行详细介绍。如果读者想系统了解请点击维基百科原词条Polymorphism (computer science)。
-
在Java中,方法重载(Method Overloading)属于Ad hoc polymorphism。在这种模式下,我们使用同一个方法名字和返回值,不同的方法参数和类型来区分不同的方法。比如String类中,多个valueOf使用不同的参数类型区分。
//code 1-1 public static String valueOf(boolean b) { return b ? "true" : "false"; } public static String valueOf(char c) { char data[] = {c}; return new String(data, true); } -
我们可以把Parametric polymorphism理解为泛型编程
//code 1-2 ArrayList<String> list = new ArrayList<>(); list.add("generic programming"); -
Subtyping即是我们最熟悉的一种多态,它描述的是subtype和supertype之间的一种可替换关系,比如下面代码
//code 1-3 Charsequence s = new String("bigcat");String实现了Charsequence,在这里我们说String是Charsequence的subtype(String is a subtype of Charsequence)。
Subtyping类似于集合中的”包含关系(⊆)”。在上面的例子中,可以理解为String是Charsequence的子集。因为它继承自Charsequence,因此使用Charsequence来表达String满足类型安全。
解决黑苹果Monterey蓝牙睡眠后不工作问题
自Monterey(macOS 12.x)以来,博通BCM94360的网卡蓝牙模块可能会出现问题,具体表现为睡眠唤醒后,蓝牙会出现睡死的情况,即需要进入系统把蓝牙关了重新打开才能正常工作。
苹果切换到Apple silicon后,貌似Opencore现在对Hackintosh也没那么上心了,蓝牙问题已经挺久。现在曲线救国的办法是在睡眠之前把蓝牙关闭,睡醒后再打开,这样会省事很多。我们当然不会手动去做这个事,mac下刚好有个app叫sleepwatcher,可以监控睡眠和唤醒。
准备工作
-
下载sleepwatcher
推荐官网直接下载,地址: https://www.bernhard-baehr.de/。(地址可能需要翻墙才能访问)
-
安装blueutil
blueutil是一个蓝牙工具,可以通过命令打开和关闭蓝牙,推荐使用homebrew下载
brew install blueutil
安装sleepwatcher
首先通过终端进入sleepwatcher的文件夹,以我的为例,版本为sleepwatcher_2.2.1
cd sleepwatcher_2.2.1
sudo cp ./sleepwatcher /usr/local/sbin
sudo cp ./sleepwatcher.8 /usr/local/share/man/man8
#创建数据文件夹,这个可以自定义,如果选择不同的路径,下面的路径也必须跟着修改
mkdir ~/.sleep
EIP55-以太坊账户地址校验算法
以太坊账户地址是一个40字符的hex string,细心的朋友可能会发现账户地址有些字母包含了大写字母和小写字母,但实际交易时,用小些地址也可以正常执行操作。
查了一下资料,发现原来包含大写字母的是经过了校验和(checksum)的地址
0x7cb57b5a97eabe94205c07890be4c1ad31e486a80x7cB57B5A97eAbe94205C07890BE4c1aD31E486A8
上面两个地址的区别是,前者不包含校验和(checksum),后者是包含校验和的地址。这个校验和有什么作用呢?因为以太坊地址本身不包含校验信息,一旦用户输入错误,没有一种机制校验,该交易将会永远丢失。
为了解决上面的问题,2016年有人在github提了一个Improvement Proposal《Yet another cool checksum address encoding》,用一种向后兼容的校验和算法对账户地址进行checksum。这种算法得满足下面条件:
- 向下兼容
- 保持账户地址的长度和信息都不发生变化
- 足够低的碰撞概率
上面提到的proposal提出了一种算法来解决这个问题,该算法原文描述如下:
In English, convert the address to hex, but if the ith digit is a letter (ie. it’s one of
abcdef) print it in uppercase if the ith bit of the hash of the address (in binary form) is 1 otherwise print it in lowercase.
上面描述的意思需要结合代码看才更加清晰,我用自己的语言描述如下:
先把账户地址经过digist再转为hex string,然后遍历用户原本的地址,如果hex string和原地址对应位置的字符是一个字母时,把原地址的字符转为大写字符,否则是一个小些字符。
该算法最终被采纳为以太坊的标准,EIP-55。它的实现原理实际上非常简单,代码甚至都不到10行,非常简洁。下面是EIP55的JS实现。
const createKeccakHash = require('keccak')
function toChecksumAddress (address) {
address = address.toLowerCase().replace('0x', '')
var hash = createKeccakHash('keccak256').update(address).digest('hex')
var ret = '0x'
for (var i = 0; i < address.length; i++) {
if (parseInt(hash[i], 16) > 7) {
ret += address[i].toUpperCase()
} else {
ret += address[i]
}
}
return ret
}
参考资料:
Vitalik Buterin, Alex Van de Sande, “EIP-55: Mixed-case checksum address encoding,” Ethereum Improvement Proposals, no. 55, January 2016. [Online serial]. Available: https://eips.ethereum.org/EIPS/eip-55.
Ethereum Address Has Uppercase and Lowercase Letters
shadowsocks rc4-md5算法介绍
shadowsocks协议早期使用RC4加密算法用于加密数据,不过因为每次数据都适用同一个密钥流加密,存在很大的安全隐患,后面更新了RC4-MD5算法。
即便关于RC4-MD5协议的资料很难找到,而且RC4-MD5算法现在也不在安全,但还是有必要介绍一遍,因为它简单,很便于理解,在后期也会展示RC4算法的缺陷。
RC4-MD5本质上还是RC4对数据进行加密。MD5的意思是对key进行MD5运算,得到RC4的key,最终会被RC4算法用于生成密钥流。简单来说,用户的密码会经过下面步骤转换为RC4的keystream
- k1 = toBytes(password)
- k2 = ssKey(k1)
- rc4-md5-key = md5(toBytes(k2,iv))
手把手使用Java实现一个Socks5代理
1. 前言
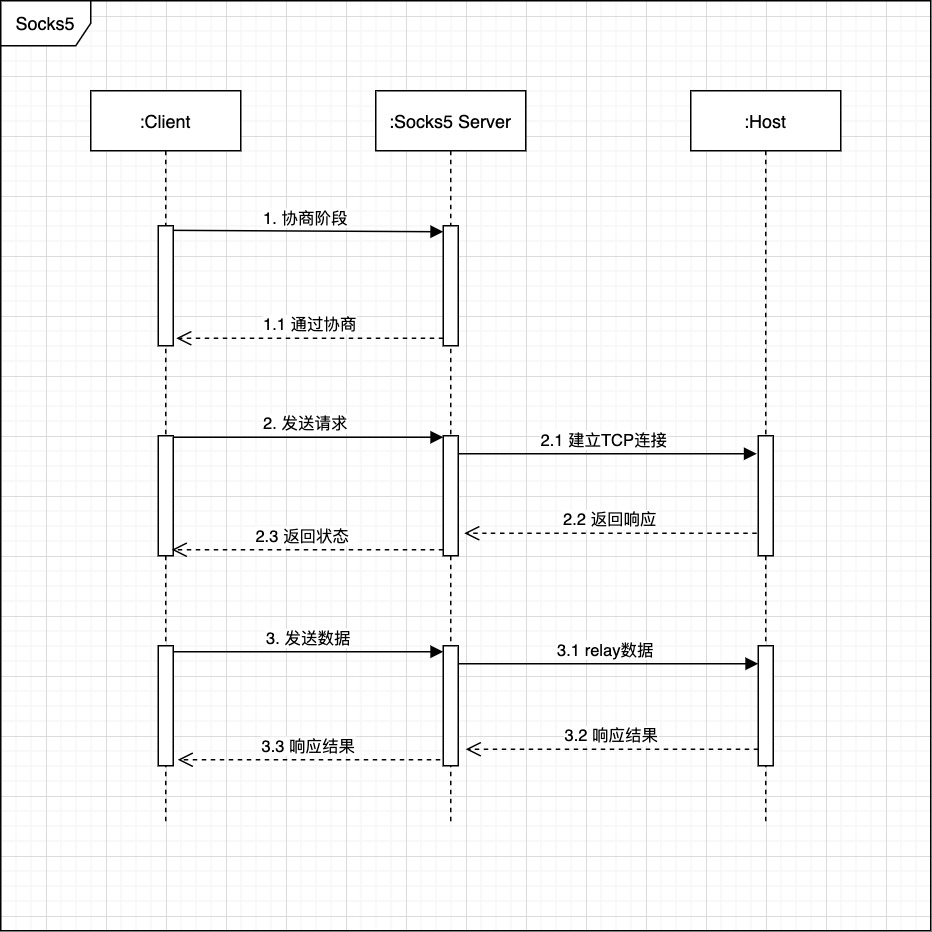
上一篇文章介绍了socks5协议的工作过程和协议的细节,通过上一篇文章我们可以认识到socks5协议主要有3个阶段,分别为: 协商、请求,转发(Relay)。本文将手把手使用Java语言实现一个简单的socks5代理
特别提醒: 本文目的仅作为加深socks5协议理解,其中的代码并不是严谨的代码,也没考虑其他的情况。在实际的开发过程中,需要考虑更多的意外情况。
上一篇文章中有一张时序图展示了socks5的大概工作过程,本文将使用Java把这些过程一一实现。