在编程中I/O是必不可少的操作。日常中,我们最常接触的就是Blocking I/O,也就是常说的阻塞I/O。相信你也听过同步非阻塞I/O(Non-Blocking I/O),异步I/O(Asynchronous I/O)。
要理解这些I/O模型并不是一件容易的事,相信你也在网上看到许多人尝试对这些概念解释,不过我认为目前并没有什么文章能对它们解释的比较清晰的文章。尤其是很多一知半解的人胡乱举例,更是加深理解难度。
知识准备
阅读本文之前,希望读者具备以下的知识,否则看了也是一脸懵。
- 了解你所知语言中的基本I/O操作
- User space & Kernel space 的概念
- 理解File Descriptor。如果不懂,请移步理解linux中的file descriptor(文件描述符)。建议读者不管对file descriptor有没有了解,都去阅读这篇文章,对你理解I/O模型会有非常大的帮助。
看完了上面的内容,希望读者已经理解了下面内容
- 程序无法直接访问硬件资源,对磁盘(硬件)的读写需要发起system call,让kernel处理。
- 大部分和I/O有关的system call,都需要把fd(file descriptor)作为参数传递给kernel。
一次I/O操作经历了什么
在正式开始之前,先对I/O流程有一个感性的认识。
public static void main(String[] args) throws Exception{
//fd已经在构造FileInputStream创建
FileInputStream in = new FileInputStream("/tmp/file1.txt");
FileOutputStream out = new FileOutputStream("/tmp/file2.txt");
byte[] buf = new byte[in.available()];
in.read(buf);
out.write(buf);
}
上面的代码是Java中典型的BIO,读取一个文件的内容,输出到另一个文件中。那么这个过程会发生那些事呢?请看下图
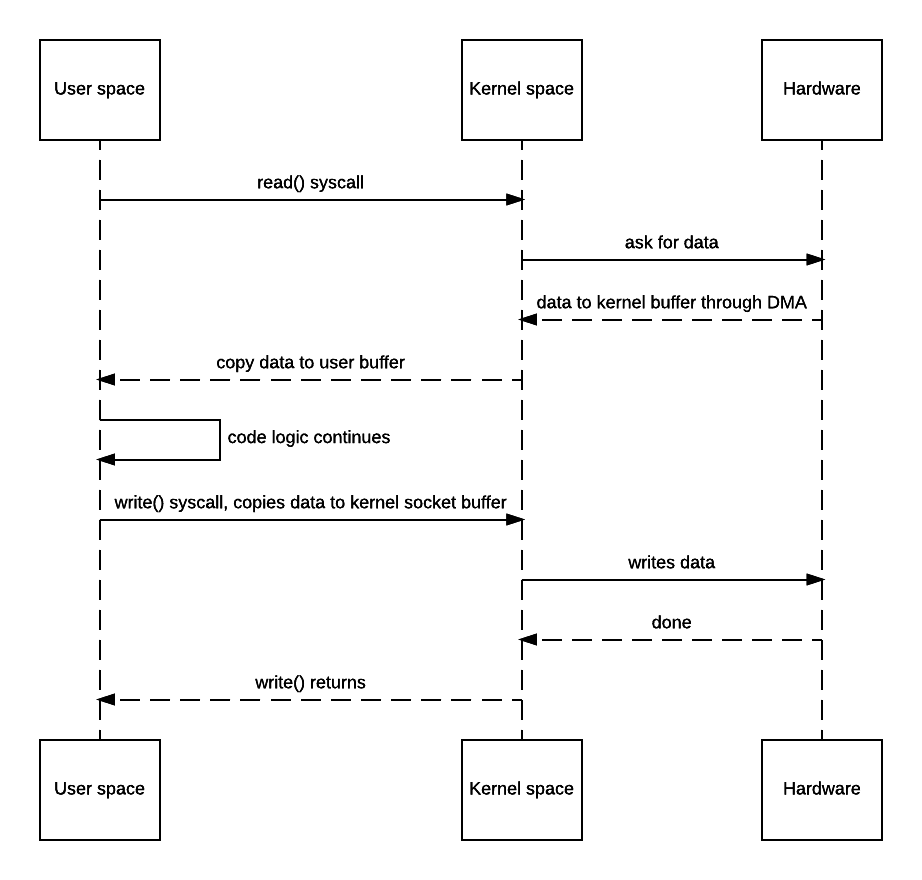
发生了什么呢?
- in.read(buf)执行时,JVM向kernel发起system call
read() - 操作系统发生上下文切换,由用户态(User mode)切换到内核态(Kernel mode),把数据读取到Kernel space buffer
- Kernel把数据从Kernel space复制到User space,同时由内核态转为用户态。
- JVM继续执行out.write(buf)这行代码
- 再次发生上下文切换,把数据复制到Kernel space buffer中。kernel把数据写入文件。
从上面可以看出一个I/O操作,通常而言会发生下面的事
- 两次上下文切换(User mode 和 Kernel mode之间转换)
- 数据在Kernel space 和 User space之间复制
I/O模型种类
在Linux中一共有5种I/O模型,分别如下:
- blocking I/O
- nonblocking I/O
- I/O multiplexing (
select、poll、epoll) - signal driven I/O (
SIGIO) - asynchronous I/O (the POSIX
aio_functions)
下面将逐个介绍这些I/O,以及它们的优缺点。
Blocking I/O
上一个小节展示了阻塞I/O的读写过程。当程序向kernel发起system call read()时,进程此时阻塞,等待数据就绪(等待kernel读取数据到kernel space)
Process –> systel call –>kernel –> hardware(hard disk)
上面的阻塞并正常情况不会带来太大的资源浪费,因为Kernel从磁盘中读取数据这过程瞬间就能完成。但如果是网络I/O,情况就会变的不同,比如Socket。

上图是blocking I/O发起system call recvfrom()时,进程将一直阻塞等待另一端Socket的数据到来。在这种I/O模型下,我们不得不为每一个Socket都分配一个线程,这会造成很大的资源浪费。
Blocking I/O优缺点都非常明显。优点是简单易用,对于本地I/O而言性能很高。缺点是处理网络I/O时,造成进程阻塞空等,浪费资源。
注: read() 和 recvfrom()的区别是,前者从文件系统读取数据,后者从socket接收数据。
Non-Blocking I/O
非阻塞I/O很容易理解。相对于阻塞I/O在那傻傻的等待,非阻塞I/O隔一段时间就发起system call看数据是否就绪(ready)。
如果数据就绪,就从kernel space复制到user space,操作数据; 如果还没就绪,kernel会立即返回EWOULDBLOCK这个错误。如下图
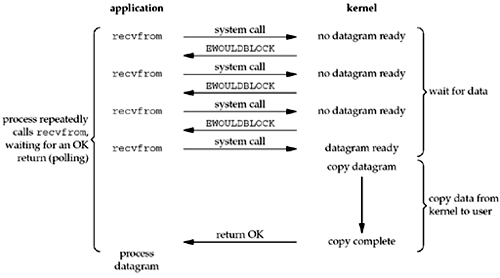
可能细心的朋友会留意到,这里同样发起system call recvfrom,凭什么在blocking I/O会阻塞,而在这里kernel的数据还没就绪就直接返回EWOULDBLOCK呢?我们看看recvfrom函数定义:
ssize_t recvfrom(
int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen
);
在这里能看到recvfrom有个参数叫flags,默认情况下阻塞。可以设置flag为非阻塞让kernel在数据未就绪时直接返回。详细见recvfrom。
Non-blocking I/O的优势在于,进程发起I/O操作时,不会因为数据还没就绪而阻塞,这就是”非阻塞”的含义。
但这种I/O模型缺陷过于明显。在本地I/O,kernel读取数据很快,这种模式下多了至少一次system call,而system call是比较消耗cpu的操作。对于Socket而言,大量的system call更是这种模型显得很鸡肋。
I/O Multiplexing
I/O Multiplexing又叫IO多路复用,这是借用了集成电路多路复用中的概念。它优化了非阻塞I/O大量发起system call的问题。
上面介绍的I/O模型都是直接发起I/O操作,而I/O Multiplexing首先向kernel发起system call,传入file descriptor和感兴趣的事件(readable、writable等)让kernel监测,当其中一个或多个fd数据就绪,就会返回结果。程序再发起真正的I/O操作recvfrom读取数据。
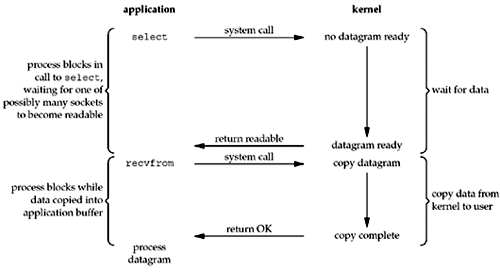
在linux中,有3种system call可以让内核监测file descriptors,分别是select、poll、epoll。
select
上图的例子就是select,我们看一下select的函数定义
int select(
int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout
);
select函数可以传入3个fd_set,分别对应了不同事件的file descriptor。返回值是一个int值,代表了就绪的fd数量,这个数量是3个fd_set就绪fd数量总和。
当程序发起system call select时流程如下
- 程序阻塞等待kernel返回
- kernel发现有fd就绪,返回数量
- 程序轮询3个fd_set寻找就绪的fd
- 发起真正的I/O操作(read、recvfrom等)
优点:
- 几乎所有系统都支持select
- 一次让kernel监测多个fd
缺点:
- 每个fd_set的大小,受限于FD_SETSIZE(默认的1024)
- kernel返回后,需要轮询所有fd找出就绪的fd,随着fd数量增加,性能会逐渐下降
更多的介绍请点击select函数查看。
poll
poll本质上和select并没有太大不同,首先看它的函数定义:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
//pollfd结构体如下
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
第一个参数fds是一个结构体数组,因此poll不受限FD_SETSIZE的值。它优缺点跟select差不多。另外是只有linux支持poll。
epoll
select和poll都是等待内核返回后轮询集合寻找就绪的fd,有没有一种机制,当某个fd就绪,kernel直接返回就绪的fd呢?这就是epoll。
epoll是一种I/O事件通知机制,linux kernel 2.5.44开始提供这个功能,用于取代select和poll。epoll内部结构用红黑树实现,用于监听程序注册的fd。和epoll相关的函数共有3个,分别如下
-
epoll_create1
创建一个epoll实例并返回它的fd -
epoll_ctl
操作epoll实例,可往里面新增、删除fd -
epoll_wait
等待epoll实例中有fd就绪,且返回就绪的fd
epoll_create1
创建一个epoll实例并返回它的file descriptor
int epoll_create1(int flags);
epoll_ctl
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
epoll_ctl用来操作epoll实例监听的fd,可以往epoll实例中新增、删除。参数解释如下:
- epdf: 即epoll_create1返回的fd
- op是operation的缩写,可为EPOLL_CTL_ADD、EPOLL_CTL_MOD、EPOLL_CTL_DEL
- fd即要监控的fd
- event即要注册的事件集合(可读、可写之类的)
epoll_wait
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
调用epoll_wait函数会阻塞,直到epoll实例监控的fd中有一个或多个fd就绪,或timeout。就绪的fd会被kernel添加到events数组中。
- epfd: 即epoll_create1返回的fd
- events events数组,就绪的fd将会放在这里
- 最大的事件数量
- 超时时间
epoll是一种性能很高的同步I/O方案。现在linux中的高性能网络框架(tomcat、netty等)都有epoll的实现。缺点是只有linux支持epoll,BSD内核的kqueue类似于epoll。
Signal-Driven I/O
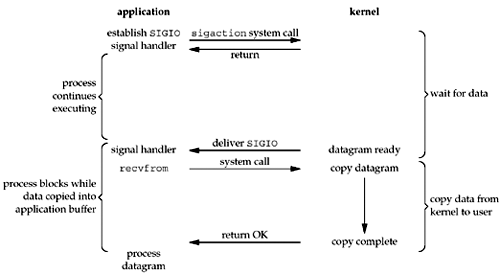
这种信号驱动的I/O并不常见,从图片可以看到它第一次发起system call不会阻塞进程,kernel的数据就绪后会发送一个signal给进程。进程发起真正的IO操作。
这种I/O模型有点复杂,且存在一些限制。有兴趣请点击Signal-Driven I/O for Sockets查看。
Asynchronous I/O
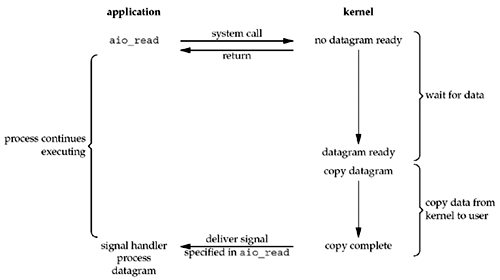
异步I/O,即I/O操作不会引起进程阻塞。请看上图,发起aio_read请求后,kernel会直接返回。等数据就绪,发送一个signal到process处理数据。
请留意图片细节,程序不需要再次发起读取数据的system call,因为kernel会把数据复制到user space再通知进程处理,整个过程不存在任何阻塞。
int aio_read(struct aiocb *aiocbp);
//aiocb
struct aiocb {
/* The order of these fields is implementation-dependent */
int aio_fildes; /* File descriptor */
off_t aio_offset; /* File offset */
volatile void *aio_buf; /* Location of buffer */
size_t aio_nbytes; /* Length of transfer */
int aio_reqprio; /* Request priority */
struct sigevent aio_sigevent; /* Notification method */
int aio_lio_opcode; /* Operation to be performed;
lio_listio() only */
/* Various implementation-internal fields not shown */
};
疑难解答
阻塞I/O和非阻塞I/O
分辨这两种I/O十分简单,阻塞I/O发起真正的 I/O操作时(如read、recvfrom等)将会阻塞等待kernel数据就绪。非阻塞I/O会不断发起system call,直到kernel数据就绪。
I/O Multiplexing是非阻塞I/O吗
很多人会混淆两者的关系,很显然,不是!
不管是select、poll、epoll都会导致进程阻塞。发起真正的IO操作时(比如recvfrom),进程也会阻塞。
I/O Multiplexing优点在于一次性可以监控大量的file descriptors。
同步I/O和异步I/O
POSIX对这两个术语定义如下:
- 同步I/O操作将会造成请求进程阻塞,直到I/O操作完成
- 异步I/O操作不会造成进程阻塞
根据上面的定义我们可以看出,前面4种I/O模型都是同步I/O,因为它们的I/O操作(recvfrom)都会造成进程阻塞。只有最后一个I/O模型匹配异步I/O的定义。
POSIX defines these two terms as follows:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes.
- An asynchronous I/O operation does not cause the requesting process to be blocked.
Using these definitions, the first four I/O models—blocking, nonblocking, I/O multiplexing, and signal-driven I/O—are all synchronous because the actual I/O operation (recvfrom) blocks the process. Only the asynchronous I/O model matches the asynchronous I/O definition.
特别注意: select、poll、epoll并不是I/O操作,read、recvfrom这些才是。
参考资料
I/O Models
https://linux.die.net
https://man7.org/
https://en.wikipedia.org/wiki/Epoll
https://gist.github.com/MagnusTiberius/bf31eb8584452f8b12c637871ba517f0
It’s all about buffers: zero-copy, mmap and Java NIO